想像一下,每當使用者打開 AI 助理,請它規劃東京五天四夜行程、比較機票、整理飯店清單;或是上傳一份財報,要求 AI 分析營收、毛利率、庫存與明年展望,表面上只是一次問答,實際上卻已在雲端資料中心裡被拆解成數千、數萬,甚至數十萬個 Token,經由 GPU、HBM、網路與電力共同支撐完成。
經過模型反覆進行推論、搜尋、摘要、重寫與校對,背後所消耗的是 GPU 算力、HBM 記憶體頻寬、資料中心電力與雲端服務成本。換言之,使用者以為的「一句話」,實質上是驅動了一整套半導體與雲端供應鏈的連鎖反應,間接影響了 SK hynix、三星電子乃至整個供應鏈的議價籌碼,並持續推升整體雲端服務的營運成本。
Token 為什麼是 AI 時代新貨幣?
Token 是 AI 模型用來讀取與產生內容的最小計量單位,它不完全等同於一個中文字或一個英文字母,而是模型將文字、程式碼、符號拆解後進行運算的基礎單位。無論是輸入的問題還是輸出的解答,都會被轉化為 Token ;當 AI 需要進一步閱讀長篇文件、檢索外部資料、呼叫工具或執行多輪推理時,Token 的消耗量便會呈指數型增長。
這項技術特性正從根本上改變軟體產業的商業模式。過去數十年軟體產業的核心是 SaaS(Software as a Service,軟體即服務),採取按月或按人頭計費的訂閱制。然而現在的生成式 AI 成本結構本質不同,核心成本不在於「帳號/帳密」的維護,而在於每一次模型進行的推論(Inference)。
如果是傳統 SaaS 模式,即便多增加一名使用者,邊際成本增加相對有限;然而 AI 服務模式,則是讓重度使用者頻繁要求模型分析長文本、編寫程式碼或處理複雜資料,其產生的推論成本可能遠高於十名輕度使用者。
因此 AI 服務正加速從「按人頭收費」轉向「按使用量收費」,其核心計量單位即為 Token。這種新型態的計價邏輯可被定義為 TaaS(Token as a Service,Token 即服務)。未來,使用者購買的不再僅是固定的月費方案,而是一段推論能力、一組 Token 額度,或是一種依任務複雜度浮動的 AI 使用權。
「思考 Token」帶來成本新挑戰
隨著技術演進,主流 AI 模型(如具備思考鏈機制的推理模型)導入了「思考 Token」(Reasoning Tokens)的概念。AI 在輸出最終答案前,會在後台進行自我推理、辯證與糾錯。這意味著即使最終輸出的字數很少,AI 在後台「思考」時所燃燒的 Token 數量也可能極其龐大,這讓 TaaS 的計價模型變得更加動態且複雜。
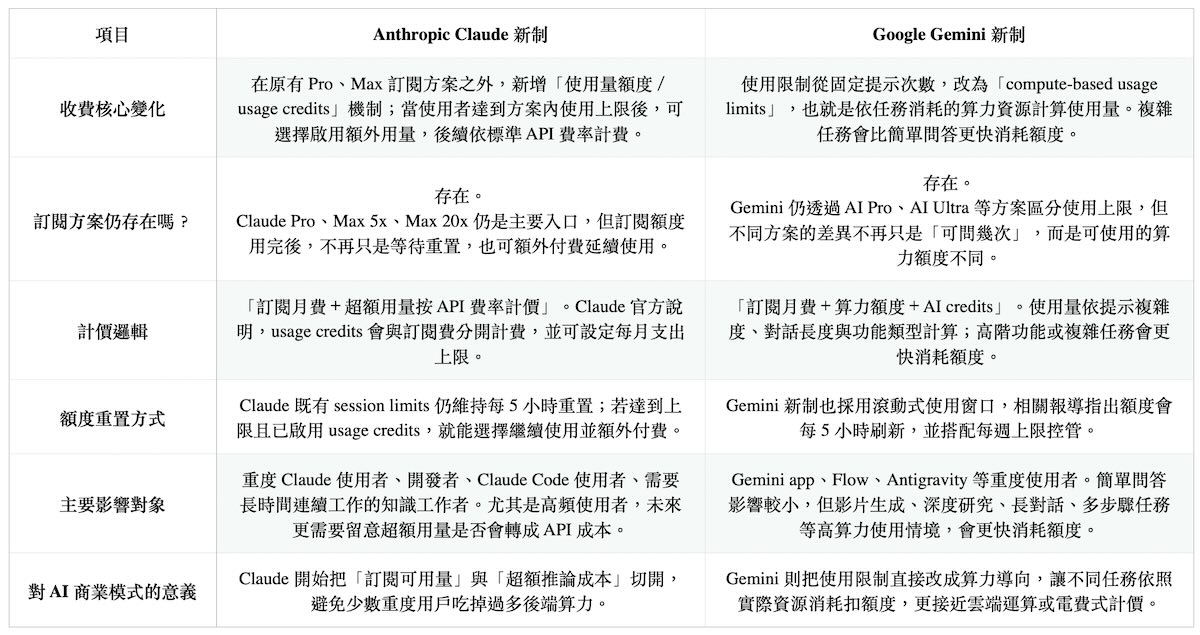
上述的論述並不是口頭說說,近來 Claude 與 Gemini 的收費調整,正好說明 AI 服務並不是單純從訂閱制直接跳到 Token 計價,而是進入「訂閱制外殼、使用量才是核心」的新階段。
這代表 Claude 的新制並不是單純提高訂閱價格,而是把「人類互動」與「程式自動化」兩種使用情境切開。過去開發者可能用同一個 Claude 訂閱額度,同時聊天、寫程式、跑腳本、串第三方工具。
但當 AI Agent 開始能在背景自動執行任務,模型呼叫次數可能遠高於一般聊天,原本「一式訂閱用到飽」的邏輯就很難支撐。對 AI 公司來說,最需要被控管的不是帳號數,而是背後被不斷呼叫的推論量;一旦 AI 被接進開發流程、企業系統或自動化腳本,每一次背景執行都會變成實際的算力成本。
Google 的 Gemini 則走向另一種分層方式,該服務新增每月 100 美元的 AI Ultra 方案,提供比 Pro 方案高 5 倍的 Gemini app 與 Google Antigravity 使用上限;同時也將原本高階 AI Ultra 方案從每月 250 美元降至 200 美元,並保留比 Pro 高 20 倍的使用上限。
Google 官方也明確說明,Gemini app 的使用限制已改採「compute-based usage limits」,也就是依照提示複雜度、使用功能與對話長度計算,額度每 5 小時刷新,直到達到每週上限,使用者也可額外購買 AI credits 延長使用量。這說明 AI 訂閱正在從固定月費,轉向「月費+算力額度+額外加值」的混合模式;未來用戶要管理的,不只是訂閱方案,而是自己的推論預算。
不過無論是 Claude 還是 Gemini,其 AI 訂閱制並沒有消失,但使用吃到飽的邏輯正在退場。未來使用者購買的不是單純帳號,而是一段可被精準控管的推論額度;越長的上下文、越複雜的任務、越高階的模型,都會更快消耗這張看不見的 AI 電表。
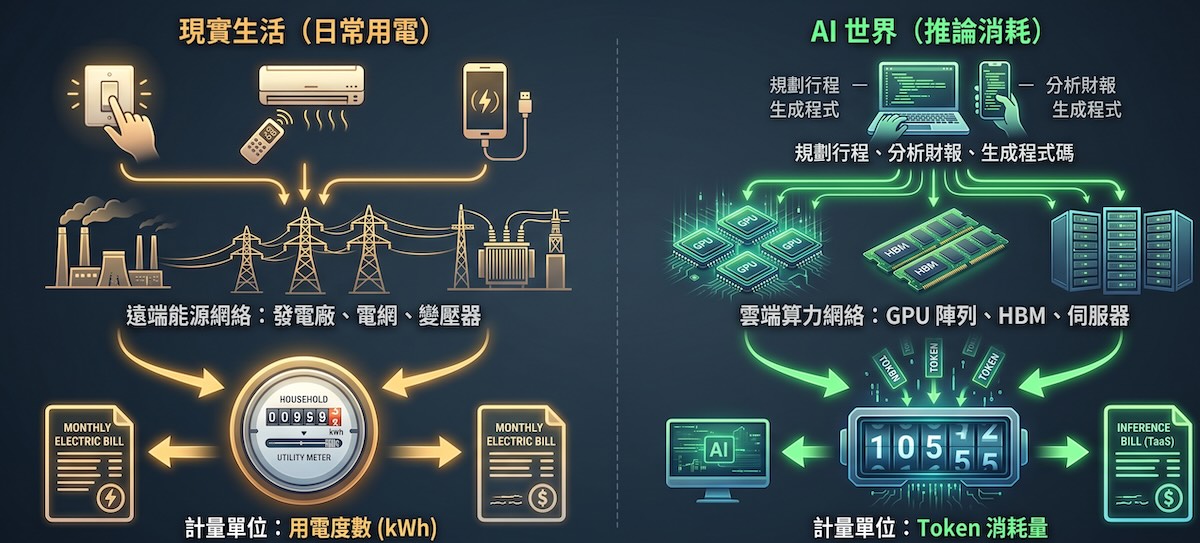
AI 的 Token 消耗亦是如此;使用者撰寫郵件、整理會議紀錄或生成程式碼,本質上都是一次又一次的推論用電,由模型供應商與雲端平台即時記錄。由於 AI 模型每回答一次都需要重新消耗硬體算力,無法像傳統軟體那樣以接近零的邊際成本無限複製,這迫使大廠在推行訂閱制的同時,必須嚴格限制用量、調整模型級別,或提供更精細的 API 計價。
例如 API 聚合平台 OpenRouter 採用的 Pay-as-you-go(按實際使用量付費) 模式,無最低消費與綁約限制,讓使用者透過單一 API 即可存取數百個模型。這印證了 AI 服務正逐步往雲端運算市場靠攏:市場交易的不再是套裝軟體,而是被即時計量的算力與推論結果。
而為了優化這張「雲端電費單」,市場上推出了「提示詞快取」(Prompt Caching)技術。當企業或開發者反覆輸入相同的長文本(如企業內部規範、法規條款或歷史對話)時,雲端平台會將這些固定的 Token 快取在記憶體中,當下次呼叫相同內容時,費用通常能大幅調降 50% 以上。這項機制將成為企業未來控管 AI 營運成本的關鍵手段。
中國模型為何在 Token 戰場快速崛起?
Token 經濟學的成形,也同步改變了全球 AI 競爭力的觀測指標;過去業界習慣以模型參數規模、基準測試榜單分數(Benchmark)或訓練成本來評估 AI 實力,如今更具實質商業意義的指標則是,誰的模型處理了最多的 Token?誰能以最低的成本提供高效率的推論?
當 AI 應用從單純的聊天工具走向企業工作流、代理式 AI(AI Agent)與內部系統整合時,每一次的任務規劃、文件檢索、改寫與校對都會密集消耗 Token。在這場長跑中,誰能將推論成本壓到最低,誰就能將 AI 推進至更深層的商業場景中。
邊緣 AI 的分流抗衡
隨之而來的 TaaS 高昂成本,也加速了運算架構的分流,進而催生了邊緣 AI(Edge AI)的崛起。當企業與個人使用者意識到長期向雲端支付推論費將帶來沈重的財務負擔時,將部分任務轉移至在地端處理便成為必然趨勢。
透過搭載高晶電晶體與 NPU(神經網路處理器)的 AI PC、智慧型手機或邊緣設備,許多日常、隱私敏感度高、或重覆性高的初階推論任務,可以直接在地端裝置運算。這種模式下,使用者消耗的是自有裝置的電力的與晶片算力,無需向雲端大廠支付 Token 費用。未來的 AI 算力地圖,預期將走向「複雜任務走雲端付推論費,日常任務走地端免推論費」的雙軌並行模式。
AI 商業模式正在重寫
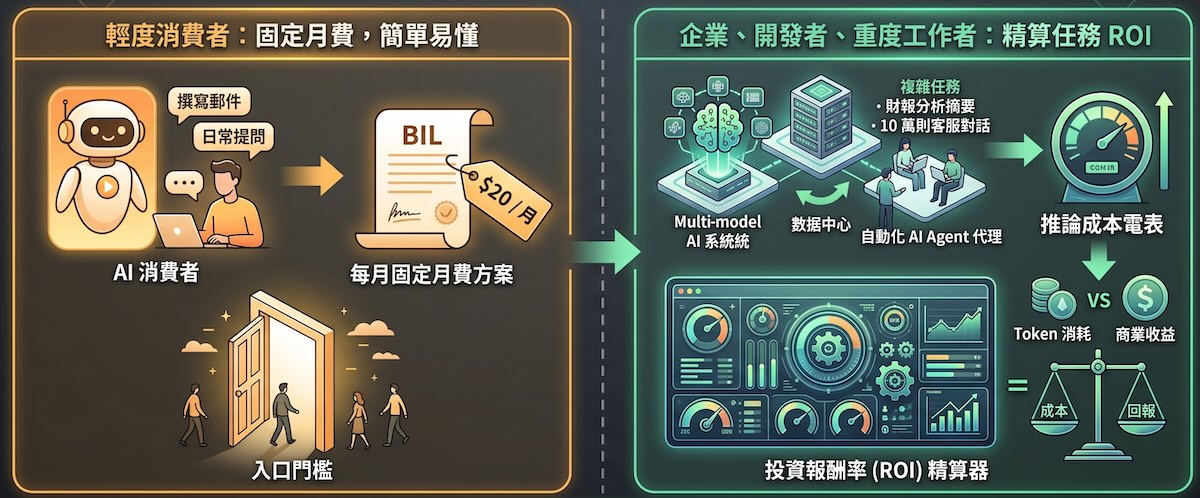
未來,AI 服務的收費型態將不再局限於「每月 20 美元」的單一訂閱制。對輕度消費者而言,固定月費仍是最易理解的門檻;但對企業客戶、開發者與重度工作者來說,精算每個任務的「投資報酬率」(ROI)將成為核心課題。