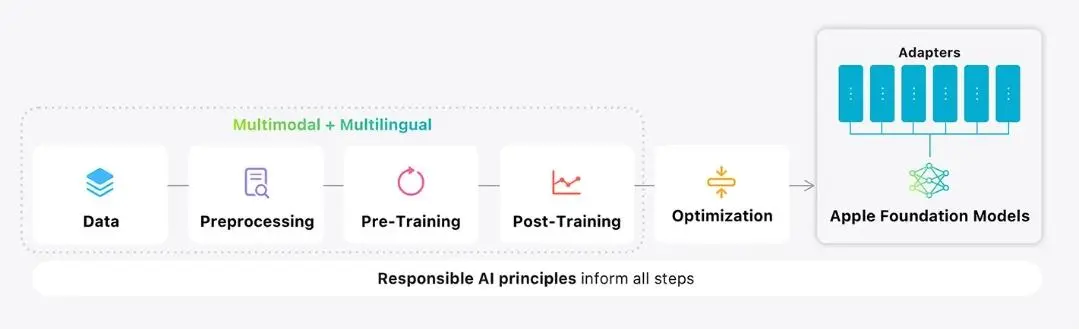
這項技術策略的背後,是蘋果長期以來在優化本地 AI 性能上的探索。幾年前,蘋果就曾研究過如何在記憶體受限的設備上,透過在 RAM 和快閃儲存之間按需交換大型語言模型(LLM)部分內容,來運行比設備記憶體容量更大的模型。雖然最終的解決方案有所不同,但這充分展現了蘋果致力於在輕量級設備上提供高性能 AI 的決心。
簡而言之,「專家混合模型」(MoE)是種突破性的 AI 模型設計。它不再依賴一個龐大、單一的模型來處理所有任務,而是將其分解為多個較小的子網路,或稱之為「專家」。這些「專家」只會在處理與其專長相關的任務時才被激活。舉例來說,如果您的提示與烹飪相關,那麼只有負責烹飪領域的專家會被喚醒並參與計算,而其他專家則保持休眠狀態。這種模組化設計使得整體模型雖然依然龐大,但其響應速度更快,且往往更為精準,避免了所有提示都必須通過一個龐大統一模型而導致的效率低下。
此外,蘋果還加入了一種巧妙的設計,旨在平衡局部上下文理解與全局宏觀視野,稱之為「交錯全局與局部注意力層」(Interleaving Global and Local Attention Layers)。最終,這一切技術的結合,成就了一個高度模組化、高效且可擴展的 AI 模型,它不僅運行速度更快、資源消耗更少,同時也保持了卓越的智能水平。