蘋果研究團隊近日發表一項新研究,指出大型語言模型(LLM)不僅能理解文字,當其接收由音訊與動作模型產生的文字描述後,也能有效推斷使用者正在進行的日常活動。這項研究揭示了蘋果在多模態 AI 感知上的布局方向,也為未來的活動追蹤、健康偵測與智慧情境推論帶來更大的想像空間。
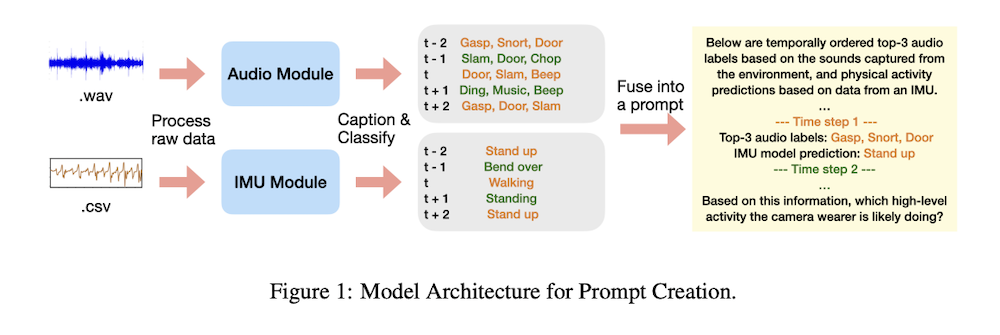
這篇名為《Using LLMs for Late Multimodal Sensor Fusion for Activity Recognition》的論文指出,LLM 可用於「後期多模態融合」(late fusion),將來自音訊模型與 IMU 動作模型(加速度計與陀螺儀)的輸出進行整合與分析。研究人員表示,這種結合方式能在感測資料不足、無法直接提供完整情境時,協助系統更精準地理解使用者的行為。
值得注意的是,這項研究展現一種可能的方向,那就是 LLM 不必直接看到影音內容,也能藉由其他模型生成的文字敘述理解行為,這也可能是蘋果未來在隱私與裝置端運算間取得平衡的方式。像是在 Apple Watch、iPhone 或 Vision Pro 等裝置上,系統可在不處理原始音訊或大量個資的前提下,仍具備更高階的情境理解能力。