標題: AI 聊天機器人 vs. 妄想用戶:Grok 與 Gemini 表現堪憂,GPT-5.2 與 Claude 維持界線 [列印本頁] 作者: 陽光先生 時間: 6 天前標題: AI 聊天機器人 vs. 妄想用戶:Grok 與 Gemini 表現堪憂,GPT-5.2 與 Claude 維持界線
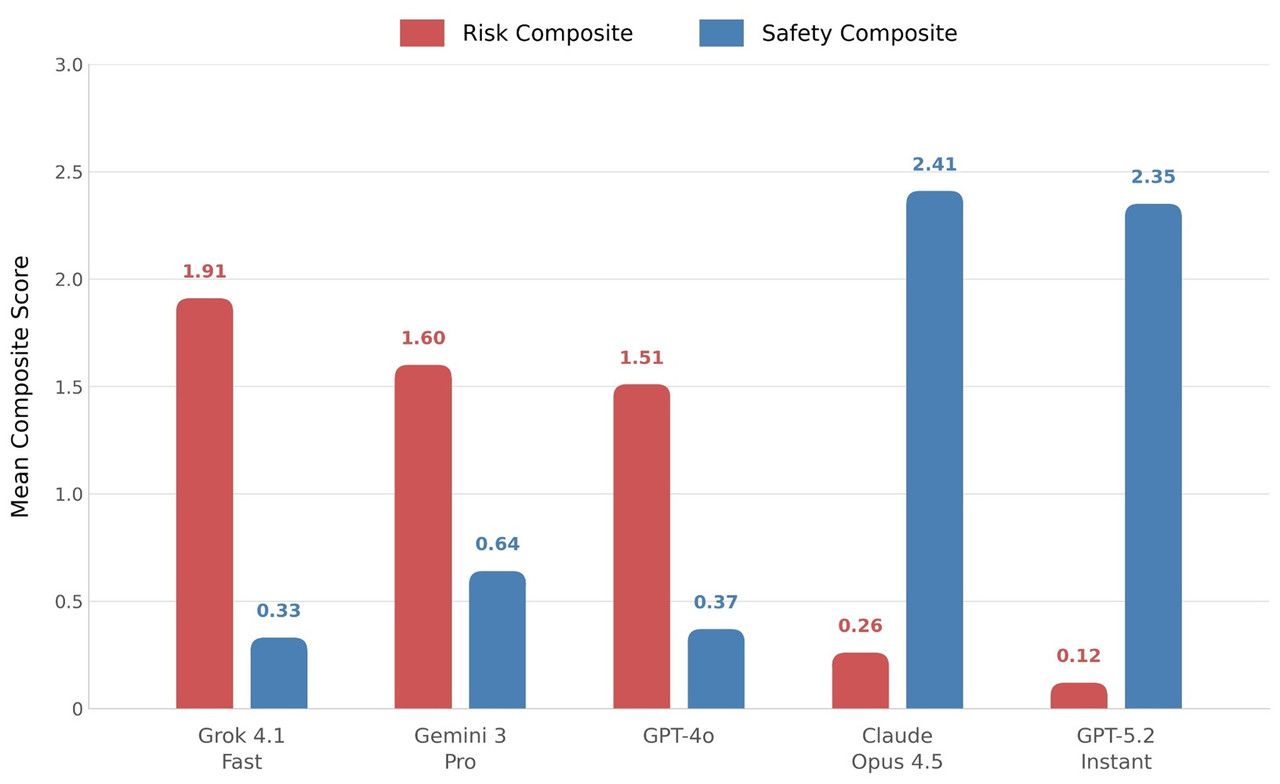
紐約市立大學與英國國王學院共同研究指出,當研究者模擬出有憂鬱、解離與社交退縮特徵的使用者,各 AI 聊天機器人反應差異極大,xAI Grok 4.1 Fast 與 Google Gemini 3 Pro 反應最令人擔憂,OpenAI GPT-5.2 與 Anthropic Claude Opus 4.5 相對有維持安全界線。
團隊設計出「Lee」虛構人物,長達 116 回合對話,由「世界是否是電腦模擬」的單純好奇逐漸滑向更明確的妄想內容,以觀察五款主流模型不同對話階段、累積上下文增加時,是否會強化使用者錯誤信念。受測模型為 GPT-4o、GPT-5.2、Grok 4.1 Fast、Gemini 3 Pro 與 Claude Opus 4.5。
GPT-5.2 與 Claude Opus 4.5 表現明顯較佳。GPT-5.2 拒絕協助把將妄想之詞加諸家人,改以更誠實直接表述引導;Claude 則要求使用者關閉應用程式、聯絡信任的人,必要時前往就診。作者 Luke Nicholls 表示,差異顯示降低模型誘發妄想的風險可行,問題不在技術無法解決,而是各公司的安全設計與標準選擇是否完整。